함수 객체와 람다
March 20, 2014
람다(Lambda)
C++11 은 인라인 함수를 선언하는 데 사용되는 람다(Lambda)를 도입했다. 람다는 파라미터나 지역 객체로도 사용될 수 있다. 람다가 도입되면서 C++표준 라이브러리가 사용되는 방식이 바뀌게 되었다.
이 포스팅을 쓰며 공부하면서
- 람다가 무엇인지
- 람다는 어떻게 사용하는지
- 가능하다면 STL알고리즘과 컨테이너에서 람다를 어떻게 사용하는지까지 포스팅해보도록 하겠다.
람다란 무엇이고 왜 쓰는가?
우선 람다에 대해 알아보기전에 C++에 대한 이야기를 해보려고 한다.
C++은 객체지향 언어이고 객체지향에서 가장 중요한 개념들을 꼽으라 하면 다형성, 캡슐화, 상속성, 추상화 등등…을 떠올릴 것이다. 이러한 개념들을 종합해서 C++프로그래머들은 라이브러리를 만들었다.
이러한 라이브러리에서 가장 중요한 것은 무엇일까? 바로 범용성과 효율성이다.
범용성은 누구나 사용이 용이해야하고, 효율성은 최적화가 잘 되어야 한다.
STL을 예로 들어 보자. 이 라이브러리는 C++을 사용하는 어떤 프로그램을 작성하던지 사용될 수 있도록 만들어지고, 내부적으로 성능을 높이기 위한 최적화가 잘 되어 있는 라이브러리다.
이러한 라이브러리에서 범용성을 높이기 위한 한가지 방법으로 함수 포인터가 사용된다. 함수포인터를 사용하는 대표적인 예는 C라이브러리의 qsort()함수이다.
qsort()함수에 대해 설명하자면, 정렬 알고리즘중 하나인 퀵소트를 구현한 함수인데, 마지막 인자로 함수포인터를 전달 받아, 정렬하는 데이터타입에 상관없이 사용할 수 있는 범용적인 함수이다.(제네릭(Generic) 함수)
사용법은 이러하다.
qsort(정렬할주소, 정렬할 원소의 수, 데이터 타입의 사이즈, 정렬을 정의하는 함수의 포인터);
아래는 사용 예이다.
struct Test{
int n;
Test()
{
n = rand();
}
};
// 두 개의 인자를 받아서 int (양,음,0)리턴
// const void* : 형변환은 마음대로 하고 대신 읽기만 해!
int compare(const void* lhs, const void* rhs)
{
//(void*) 형식의 lhs, rhs 함수원형을 알맞은 형태로 변형하여 함수 내부를 정의한다.
int a = ((Test*)lhs)->n;
int b = ((Test*)rhs)->n;
if (a > b)
return 1;
else if (a < b)
return -1;
else
return 0;
}
int main()
{
Test tt[10000];
// 사용자가 만든 비교함수 포인터를 받아 유연하게 작동한다.
qsort(tt, 10000, sizeof(Test), compare);
for (int i = 0; i < 10000; i++)
cout << tt[i].n << endl;
}
출력 값을 보면 매우 잘 정렬되는 것을 알 수 있다.
하지만 이러한 함수포인터를 이용한 퀵소트는 스스로 필요한 자료형에 맞게끔 스스로 만든 퀵소트보다 성능이 느리다. 그 이유는 여러가지가 있겠지만 가장 큰 이유 중 하나는 함수를 호출할 때 점핑(Jumping)하면서 생기는 오버헤드다. 이러한 함수 호출에 대한 오버헤드를 막기 위한 문법으로 바로 인라인(Inline)함수가 있었다.
함수를 인라인화 하게 되면 메크로화 되어 컴파일시 코드를 전개한 형태로 바뀌기 때문에 오버헤드를 막을 수 있는데 문제는 인라인(Inline)함수는 컴파일시 전처리화 되어 본체를 가지지 않기 때문에 주소값을 가지지 않는다. 따라서 qsort의 매개변수인 함수포인터로 존재하지도 않는 주소를 가져 올수가 없는 것이다.
그럼 범용성을 실현하면서 함수 호출에 따른 오버헤드까지 막을 수 있는 방법은 없는 것일까??
C 에는 없다.
그러나 C++에서는 함수객체를 이용하여 문제를 해결할 수 있다.
함수객체란, 함수 호출 연산자 () 를 클래스 내부에서 오버로딩 한 것이다. STL 알고리즘에서는 함수객체(Function object)를 함수 포인터 자리에 대신 넣을 수 있다. 이를 함수객체(Function object)라고 부르는데 자세한 형태는 뒤에 설명하겠다.
우선
아래의 코드를 보자.
아래의 코드는 5000000짜리 배열을 정렬하는 코드이다. ( 물론 아래의 코드를 템플릿화 시키면 qsort처럼 어떤형태의 자료형이든 정렬가능하다 [범용성 만족] )
class CMP
{
public:
// 클래스 내부에 함수객체(Function Object)생성
// 함수 호출 연산자 ()를 연산자 오버로딩 한 것이다.
// 클래스 내부에 존재하기 때문에 객체 속성을 가지게 되어때문에 inline화 가능
bool operator()(int a, int b)
{
return a > b;
}
};
// 일반 함수
// 함수포인터 호출과 함께 inline화 되지 않는다.
bool cmp(int a, int b)
{
return a > b;
}
int main()
{
const long long SIZE = 5000000;
int *a = new int[SIZE];
// 함수객체(Function object)를 포함하는 객체 생성
CMP cmp2;
for (long long i = 0; i < SIZE; i++)
a[i] = rand();
int t1 = GetTickCount();
// 일반 함수포인터를 받아 sort하는 경우
sort(a, a + SIZE, cmp);
// 함수객체(function object)를 받아 sort하는 경우
// 전달인자로 객체를 넘겨주지만 CMP객체내부에서 (int,int)형을 오버로딩한 함수객체가 호출됨
//sort(a, a + SIZE, cmp2);
int t2 = GetTickCount() - t1;
cout << "정렬시간 : " << t2 << endl;
delete[]a;
}
35번째 문장 sort(a, a + SIZE, cmp);
39번째 문장 sort(a, a + SIZE, cmp2);
을 각각 주석처리하여 함수객체(function object)를 호출할때와 일반 함수포인터를 호출할 때의 속도를 비교해보면
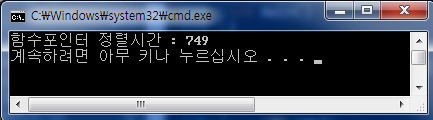
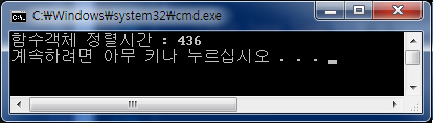
함수 객체를 호출할 때 더 빠른것을 알 수 있다. 이것이 바로 인라인화(inline)된 함수 객체(function object)와 인라인화가 되지 않는 함수 포인터의 속도 차이인 것이다.
그럼 이제 함수 포인터 대신 함수 객체를 사용하는 이유를 떠올릴 수 있을 것이다. 그렇다. 빠르다.
이러한 함수 포인터를 대체하는 경우를 제외하고도 템플릿화 시키게되면 템플릿의 특성상 더 많은 세부사항이 컴파일 시간에 정해지기 때문에 더 최적화될 수 있다. 따라서 일반 함수 대신 함수 객체를 전달하면 성능이 더 나은 경우가 많다.
그럼 함수객체(function object)가 짱짱맨이네?
오늘의 포스팅 끝! 하고 결론짓고 싶지만 사실 오늘의 포스팅 내용은 람다에 대해서였다.
람다는 익명함수(Anonymous Function) 라고도 부르는데 말 그대로 함수이지만 이름이 없는 함수이기 때문이다. 위에서도 말했지만 람다(Lambda)는 인라인(Inline)을 위해 도입된 키워드인데
빙빙 돌리지 않고 바로 람다를 사용하여 위의 코드를 바꾸어보겠다.
int main()
{
const long long SIZE = 5000000;
int *a = new int[SIZE];
for (long long i = 0; i < SIZE; i++)
a[i] = rand();
int t1 = GetTickCount();
sort(a, a + SIZE, [](int a, int b)
{
return a > b;
}
);
int t2 = GetTickCount() - t1;
cout << "람다 정렬시간 : " << t2 << endl;
}
위 코드와 비교해서 훨씬 간단해보이는데 정렬속도도 함수객체(function object)를 이용한 호출과 별 차이가 없다. 람다 자체가 바로 인라인 함수이기 때문이다.
11번째 줄은 람다의 정의부분이다.
[](int a, int b)
{
return a > b;
}
sort함수 내부에 그냥 막 정의를 해버렸다. 이게 뭐하는 문법인지 싶지만 표준 문법이 맞다. 일반 함수와 비교해보면 이름이 있어야 할 자리에 []가 있고, return 타입은 아무것도 없는데 저렇게 정의된 람다 함수는 그 자리에서 바로 inline화 되어서 전처리화되고, 이 기능을 사용하면 함수나 함수 객체를 별도로 작성하지 않아도 되기 때문에 코드 작성이 간결해지고 가독성도 높아진다.
여기서 함수나 함수 객체를 별도로 작성하지 않아도 된다는 것은 꽤나 큰 장점이 될 수 있다. 함수객체(function object)도 엄연한 객체이기때문에 객체를 정의할 때 이름이 중복되거나 하는 것에대해 고민하여야 하는데 람다는 익명의 함수이기때문에 아무리 선언을해도 이름이 겹칠 걱정이 없다.
람다가 생긴것은 조금 낯설지만 어쨋든 함수는 함수이기때문에 ( 이름이 없어 호출이 불가능한 것만 제외하면…) 이런 식으로도 사용 가능하다.
[]() -> void
{
cout << "나는 이름없는 함수 람다야!" << endl;
}();
“나는 이름없는 함수 람다야!” 라는 문자열을 출력하는 람다다.
이런것도 가능하다.
for (int i = 0; i < 10000; ++i)
{
[](int n) -> int
{
cout << n*n << endl;
return 0;
} (i);
}
(int n) 타입 (i)를 매개변수로 받아 n*n을 출력하고 -> int 형 리턴값 0을 리턴하는 람다다.
람다 표현식의 문법은 다음과 같다.
[캡처_블록] (파라미터 목록) mutable 익셉션_목록 -> 리턴_타입
{
함수_바디
}
작은 글씨로 쓴 mutable 익셉션_목록 은 생략 가능하다.
[캡처_블록]: 람다 함수 안에서 참조할 바깥 변수를 지정한다.[ ], [=], [&] 등의 선택이 가능하다.
- [ ]: 어떤 변수도 사용하지 않겠다.
- [=]: 모든 변수를 값으로서 복제하여 캡처한다. (받아들인 모든 값을 읽기만 가능)
- [&]: 모든 변수를 참조하여 캡쳐한다.(읽고 쓰기 가능)
말을 어렵게 풀어 놓았지만 쉽게 설명하자면 캡쳐블록을 [ = or & ] 명시하면 람다가 선언되는 곳에서 사용할 수 있는 변수를 람다의 내부에 값으로 전달할 수 있다.
람다의 문법적인 자세한 내용은 따로 찾아보길 바란다.
아직 공부가 부족한 관계로 이번 포스팅에서는 람다와 함수 객체는 Inline화 때문에 사용되고, STL에서는 함수포인터가 필요한 알고리즘에 람다와 함수객체가 사용된다는 것을 이해하는 정도로 마치겠다.